Neural Discrete Representation Learning
Vector Quantised-Variational AutoEncoder (VQ-VAE)

VQ-VAE를 제시한 논문으로 이후 생성모델들에 큰 영향을 준 논문이다. 이름에서 알 수 있는 것 처럼 Variational AutoEncoder (VAE)를 기반으로 하고 있는데, 생성모델 관점에서 GAN은 등장이후 엄청나게 다양한 모델들이 파생되면 놀라운 가능성을 보여주었고 Normalizing flow나 Diffusion model과 같은 새로운 방식의 생성모델이 제시되는 반면 VAE는 상대적으로 답보하고 있는 상황이었다. VAE는 여전히 data distribution을 explicit하게 추론한다는 측면에서 유용한 성질이 있었지만 타 방식에 비해 생성품질이 떨어지는 문제가 있었다. 하지만 VQ-VAE를 기반으로 이러한 단점이 크게 개선되었고 이후에 Transformer 모델들과 결합되면서 multi-modal generative model에서 놀라운 결과들을 보여주는데 핵심적인 역할을 하게 된다.
Abstract
논문은 첫 문장부터 핵심적인 문제인식을 표현하며 시작한다.
Learning userful representation without supervision remains a key challenge in machine learning.
2021년 연구를 하면서 disentangled representation learning 쪽을 알아보아야 하는 상황이었는데 해당 분야에서 매우 자주 등장하는 표현이다. Supervision 없이 representation을 학습하는데 “유용한” representation을 학습하는 것은 언뜻 생각해보아도 쉬운 문제가 아니다. “useful"과 “without supervision"의 의미를 곰곰히 생각해보면 둘은 어느정도 trade-off관계에 있지 않나라는 고민이 당시 느꼈던 딜레마였다. Abstract에서 저자는 Vector Quantised-Variational AutoEncoder (VQ-VAE)는 다음의 두 가지 측면에서 기존의 VAE와 차이점이 있다고 주장한다.
- Encoder network는 연속적인 값이 아닌 이산적(discrete)인 code값을 return한다.
- Prior가 static하지 않고 학습된다.
VAE의 학습에 사용되는 evidence lower bounde (ELBO)를 생각해보면 reconstruction하는 부분과 regularization하는 term에서 각각 연속적인 분포학습이 이루어지고 regularization에서는 prior로 Gaussian이 고정된다는 특징이 있었으므로 이러한 제약을 해소했다는 것으로 해석할 수 있다. 이를 해소하는 과정에서 핵심적인 역할을 한 것이 바로 vector quantisation (VQ)이며, quantization은 보통 연속적이 값을 갖는 수치를 이산적인 값으로 바꾸는 것임을 생각해볼때 discretization으로 생각할 수 있다. VQ의 사용은 posterior collapse문제도 해결했다고 한다.
Introduction
이 논문에서 달성하고자 하는 목표는 maximum likelihood를 높이는 모델을 학습시킬 때 latent space에 있는 데이터의 표현(feature)이 중요한 정보를 보존하도록 하는 것이다. 저자는 연구에서 목적을 달성하는데 discrete latent variables의 사용이 핵심적이었으며 이를 뒷받침하는 다양한 domain에서의 실험을 보여준다. 개인적으로 이 부분에서 InfoGAN과 목적이 상당부분 유사하다는 것을 생각했다. 물론 InfoGAN은 GAN으로 하여금 mutual information을 통한 unsupervised disentagled representation을 학습한 반면 여기서는 모델자체가 VAE를 기반으로하며, InfoGAN은 continuous code와 discrete code가 동시에 학습하도록 한 반면 여기서는 discrete code를 집중한다는 차이가 있다. 이렇게만 보면 InfoGAN이 더 가능성이 큰 것 같지만 InfoGAN을 활용한 수 많은 실험결과 continuous code와 discrete code를 unsupervised로 학습하는 어려운 task를 달성하는 것은 현재로서는 상당히 제약이 큰 환경에서만 된다고 느꼈다. MNIST나 작은 해상도의 이미지에서 회전과 글자 종류를 supervision없이 찾아낸 것은 놀라웠으나 다루는 task의 scale을 조금만 키워도 학습이 잘 되지 않았었다. 특히 sequence 데이터에 대해 적용했을 때, 진행했던 수 많은 실험에서 유용한 representation을 찾는데 실패했었다. 반면 VQ-VAE는 유용한 discrete code를 찾아 훨씬 큰 해상도의 이미지를 높은 품질로 생성할 뿐만 아니라 sequence 데이터에도 가능성을 보여주었고 실제로 이후 후속연구들에서 어마어마한 결과들을 보여준 것을 보면, VQ-VAE의 아이디어는 확장성 측면에서도 매우 중요한 연구였다고 생각한다.
저자가 제시한 VQ-VAE는 vector quantization을 통해 기본 VAE가 가지고 있던 문제인 large variance문제와 posterior collapse를 해결하고 최초의 discrete VAE모델을 제시하였다. 매우 중요한 성질 중 하나는 일단 VQ-VAE를 잘 학습시켜 얻을 수 있는 discrete latent structure는 원본 데이터의 중요한 정보를 잘 압축해 놓은 prior를 codebook의 형태로 제공한다는 것이다. 고해상도 이미지 생성모델, 혹은 multi-modal 학습에서의 어려운 점은 이미지는 pixel단위에서 볼 때 엄청나게 큰 차원을 갖는 데이터라는 것이다. 이는 언어모델에서 단어를 token으로 간단하게 표현할 수 있는과는 대비되는 성질로 이미지는 다룰 때 막대한 차원을 처리해야 하는 문제가 있었고 이는 생성과정을 어렵게 만드는 문제였으나 효과적으로 학습한 codebook은 이미지의 표현을 manageable한 수준으로 효과적으로 줄여주는 역할을 하게 된다.
저자가 제시한 main contribution은 다음과 같다.
- Posterior collapse와 variance 문제를 해소한 discrete latent기반의 VQ-VAE모델 제시
- Log-likelihood 최적화를 기반으로하는 continuous model의 성능에 필적하는 discrete latent model 제시
- Speech나 video 생성에도 사용할 수 있는 강력한 prior의 가능성 시사
- Supervision 없이 raw speech를 학습하고 speaker conversion task의 응용을 보여줌
VQ-VAE
당연(?)하게도 VQ-VAE와 가장 관련이 깊은 연구는 VAE이다. VAE는 다음의 세 가지 요소로 구성된다. 첫 번째는 posterior distribution을 추정하는 분포 $q(z \mid x)$로 encoder network를 통해 parameterize하게 된다. 이 때 VQVAE에서는 $z$를 discrete latent random variable로 모델링한다. 두 번째는 prior distribution $p(z)$이며 세 번째는 $z$를 통해 생성하는 decoder로 $p(x \mid z)$이다. 보통 VAE에서 posterior와 prior는 diagonal covariance를 갖는 normal distribution으로 가정한다. VQ-VAE는 discrete latent variable을 사용하여 posterior와 prior를 categorical distribution으로 가정한다. 이 때 categorical distribution은 embedding table의 index에 대한 분포가 되며 sampling을 통해 index를 뽑게 된다. 이렇게 sampling된 index에 해당하는 embedding을 decoder의 입력으로 주게 된다.
Discrete Latent Variable
Latent embedding space는 $e \in \mathbb{R}^{K \times D}$로 $K$는 discrete latent space의 크기로 codebook의 index 갯수로 보면 된다. $D$는 각각의 code가 갖는 embedding vector $e_i$의 차원이다. Codebook이 table형태로 2차원이라면 실제 크기는 embedding vector 차원까지 더해 3차원 크기의 블록을 생각하면 된다. 따라서 각각의 embedding vector $e_i$는 $e_i \in \mathbb{R}^{D}, i \in 1, 2, \ldots, K$로 나타낼 수 있다.
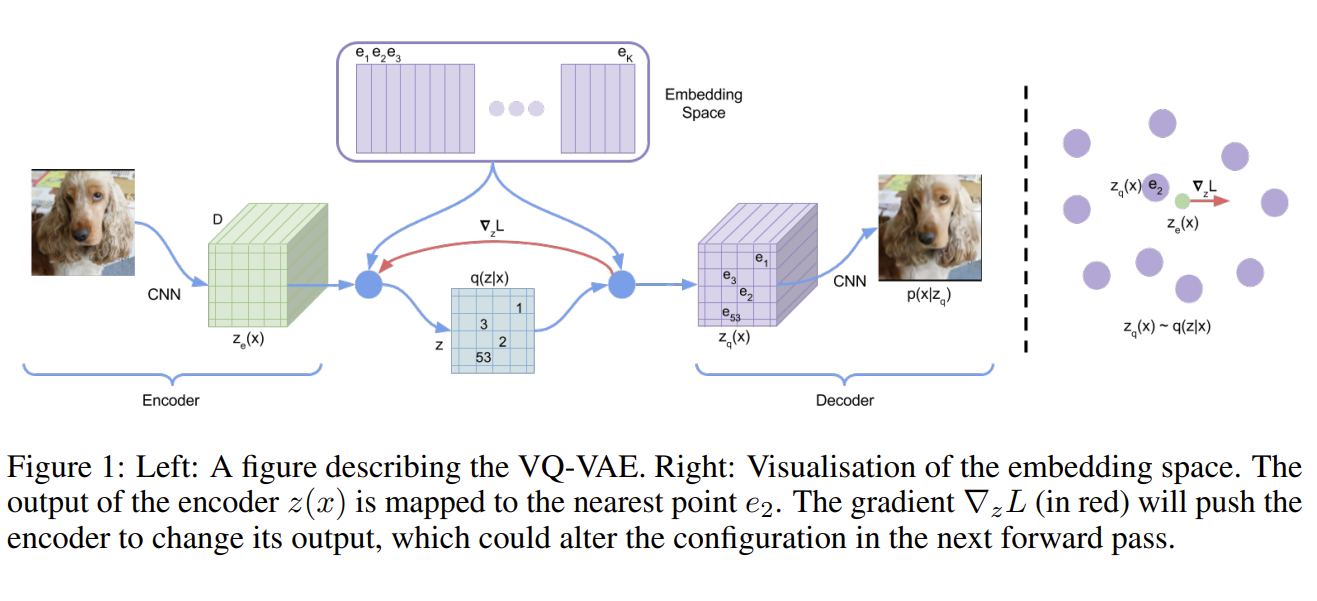
위의 구조를 따라서 가보자. 주어진 입력값 $x$는 encoder network를 통과해 $z_e (x)$를 출력하게 된다. 여기서 $z_e (x)$는 codebook에 있는 벡터가 아니다. $z$는 codebook을 뒤져서 가장 가까운 embedding vector $e_i$를 찾게 된다. 이를 식으로 나타내면 다음과 같다. 아래는 posterior categorical distribution $q(z \mid x)$를 one-hot의 형태로 표현하는 것이다.
$$ q(z=k \mid x) = \begin{cases} 1 \quad \text{for } k = \argmin_{j} \lVert z_e(x) - e_j \rVert_2 \cr 0 \quad \text{otherwise} \end{cases} $$
여기서 $q$는 가장 가까운 embedding vector에 1을 나머지에는 0을 부여하므로 one-hot vector꼴로 표현된다. Decoder에는 $z_e(x)$가 아닌 이렇게 찾아진 가장 가까운 embedding vector $e_k$가 입력으로 들어가게 된다. 여기서 저자는
$$ z_q(x) = e_k, \quad \text{where } k = \argmin_j \lVert z_e(x) - e_j \rVert_2 $$
따라서 학습 때 훈련하는 parameter들은 encoder, decoder, embedding space $e$가 되며 latent variable인 $z$의 차원은 데이터 형태에 따라 다양하게 정의할 수 있다. 예를 들어 speech데이터는 1차원, 이미지는 2차원, 비디오는 3차원의 latent feature space를 갖는다. 실제 codebook의 경우 embedding dimension까지 표현하면 차원을 하나씩 더하면 된다.
Learning
Figure 1에서와 같이 구조를 만들었을 때 가장 문제가 되는 것은 어떻게 학습을 시킬지이다. Autodiff 라이브러리를 사용하려면 gradient를 전달해주어야 하는데 가장 가까운 code를 찾아서 치환해주는 것은 당연하게도 미분가능한 형태가 아니다. 따라서 gradient를 전달할 수 없고 이는 학습시킬 수 없다는 의미가 된다. 이 논문에서 개인적으로 가장 재미있는 부분은 이를 어떻게 처리했는지인데, 결론부터 말하면 decoder input인 $z_q(x)$의 gradient를 $z_e(x)$로 복사해 전달하는 방식을 사용하였다. 그리고 이렇게 gradient를 복사해다 붙여넣는 방식을 straight-through gradient estimation이라고 한다. 정성적으로 생각해보면 forward과정에서 $z_e(x)$와 가장 가까운 code를 뽑아서 이 embedding vector $e_k$를 $z_q(x)$로 사용하였고 값이 decoder에 들어가 원래 이미지와 차이를 비교하는 어떤 recon loss를 계산하고 이 gradient가 역으로 전달될 것이다. 이 때 $z_q(x)$에서 발생한 gradient를 그대로 $z_e(x)$에 복사해서 붙인 뒤 encoder를 학습하는 것이다. 가까운 embedding vector를 찾아 바꾸는 방식이 미분가능할리 없으므로 고안한 구조에서 충분히 납득할만한 방식이라고 생각한다. 그리고 이러한 성질을 감안해 볼 때 $z_e(x)$가 codebook과 비슷할 수록 이 논리가 더 잘 성립할 것임을 짐작해 볼 수 있다. Figure 1에서 볼 때 전달되는 gradient는 $\nabla_z L$로 표현되어 있다. 그리고 이렇게 gradient가 전달되는 구조이므로 encoder와 decoder는 모두 동일하게 embedding dimension으로 $D$ 차원을 같게 가져야 한다. 학습 때 이 gradient에는 어떻게 해야 encoder가 reconstruction 낮출 수 있는지에 대한 정보를 전달해 주게 된다.
전체 loss function은 아래와 같이 계산된다.
$$ \mathcal{L} = \log p(x \mid z_q(x)) + \lVert sg[z_e(x)] - e \rVert_2^2 + \beta \lVert z_e(x) - sg[e] \rVert_2^2 $$
총 세 개의 term으로 구성되며 첫 번째 term은 reconstruction loss이다. 즉 decoder input으로부터 실제 데이터 $x$를 복원하는 reconstruction loss이다. 이 loss는 encoder, decoder학습 모두에 사용된다. Straight-through gradient estimation을 사용하므로 $e_i$는 gradient를 첫 번째 term인 reconstruction loss로 부터 받을 수 없다. 따라서 embedding space를 학습시키기위해서 vector quantization (VQ)을 사용한다. VQ는 embedding vector인 $e_i$를 encoder output인 $z_e(x)$ 방향으로 움직여 주게 된다. 이 때 움직이는 error는 L2 norm을 사용한다. 두번째 term을 보면 $e$를 $sg[z_e(x)]$ 방향으로 이동시키게 되는 것을 볼 수 있다. $sg$는 stop gradient operator로 이렇게 함으로써 embedding vector $e$가 $z_e(x)$의 gradient와 같아지도록 만들게 된다. 이 term은 dictionary update에만 사용된다. 논문본문에서 다루지는 않지만 dictionary의 item자체를 update하는 방법으로 moving average를 사용하기도 하는데 이는 Appendix A에서 다루고 있다. 논문에서 “since the volume of the embeding space is dimension less,“라고 언급하는데 이를 embedding space는 이미지의 경우 $\mathbb{R}^{h \times w \times D}$의 꼴을 가질 것임을 생각해볼 때, embedding space $h, w$는 정해지는 것이고 $D$ 방향의 경우 특별한 제한이 없으므로 별도의 제약을 주지 않을 경우 두 번째 loss를 줄이는 과정에서 불안정하게 발산할 가능성을 갖는다. (마치 contrastive learning을 할 때 negative를 멀어지게하면서 제약을 두지 않으면 발산하는 것과 비슷한 관점으로 받아들였다) 따라서 encoder ouptut자체도 embedding의 방향으로 가도록 하고 발산을 억제하기 위해서 세번째 term을 추가하게 된다. 세 번째 term은 commitment loss로 명명되었다. Stop gradient에 의해 decoder는 첫 번째 term인 reconstruction loss에 의해 훈련되며 encoder는 첫번째와 commitment loss에 의해 훈련되고 embedding은 두 번째 term에 의해 훈련된다. 당연히 stop gradient가 걸린 부분은 학습시킬 수 없다. 저자에 따르면 모델은 $\beta$에 대해서는 꽤 robust했다고 한다.
학습할 때 $z$에 대한 prior는 uniform distribution으로 가정하므로 ELBO의 KL term (regularization term)은 상수를 갖게 되어 학습단계에서 encoder parameter에는 영향을 주지 못한다. 즉 reconstruction loss term은 decoder 학습에 사용되는 것과 같다.
구현 측면에서 straight-through 방식으로 gradient를 넘기는 것은 loss계산 후 gradient를 다음과 같이 처리해주면 된다.
|
|
위와 같이 만들면 forward에서는 z_q가 그대로 사용되고 backward에서는 detach가 무시되어 z_q = z_e가 적용되므로 z_q의 gradient를 z_e에 전달할 수 있다.
VAE는 생성모델이므로 궁극적인 목적은 data distribution을 파악하는 것이며 모델의 log-likelihood는 다음과 같이 쓸 수 있다.
$$ \log p(x) = \log \sum_k p(x \mid z_k) p(z_k) $$
Decoder $p(x \mid z)$는 $z = z_q(x)$를 MAP로 추정하므로 (z \neq z_q(x) )일때 $p(x \mid z) = 0$이 된다. 따라서 summation을 풀면 결국 위의 식은 다음과 같이 근사할 수 있다.
$$ \log p(x) \approx \log p(x \mid z_q(x)) p(z_q(x)) $$
위는 Jensen’s inequality에 의해 다음을 만족한다.
$$ \log p(x) \geq \log p(x \mid z_q(x))p(z_q(x)) $$
Prior
Discrete latent의 분포 $p(z)$는 categorical distribution으로 autoregressive하게 구성할 수 있다. VQ-VAE를 훈련하는 과정에서 prior는 uniform함수로 고정하였다고 한다. 그리고 VQ-VAE의 훈련이 끝난 뒤에는 code의 순서를 구성하도록하는 autoregressve distribution을 학습시키고 inference단계에서는 ancestral sampling을 통해 생성된 code를 사용한다. Autoregressive distribution 학습을 위해 이미지에는 PixelCNN을, 오디오에서는 WaveNet을 사용하였으며 VQ-VAE의 훈련과 Prior의 훈련은 동시에 훈련한 것이 아닌 단계적으로 훈련된다.
전체 프로세스를 정리하면 다음과 같다.
- VQ-VAE 훈련 VQ-VAE를 훈련함으로써 discrete latent space를 학습한다. 이 때 codebook은 data distribution을 만들 때 필요한 유용한 discrete 정보들로 구성된다. VQ-VAE훈련이 끝나면 우리는 훈련된 encoder, decoder와 codebook을 갖게 된다.
- Autoregressive model
Codebook에서 code를 어떻게 구성해야 하는지를 훈련한다. 예를 들어 이미지를 3 X 3의 discrete code로 표현하도록 VQ-VAE를 훈련하였고 그 순서가
[1, 3, 6, 2, 8, 5, 4, 9, 7]이라고 해보자. 그러면 autoregressive하게 훈련시키므로<start>, 1, 3, 6, 2, 8, 5, 4, 9가 입력으로,3, 6, 2, 8, 5, 4, 9, 7, <end>가 대응되는 출력이 되도록 훈련시킨다. 이 훈련을 마치게 되면 실제 데이터들은 어떤 code sequence를 갖는지를 알게된다. 이제 inference단계에서는 이 prior모델로 하여금 code를 만들게 하고 이 code sequence를 훈련된 frozen decoder에 넣으면 (\hat{x})를 얻을 수 있게 된다.
Experiments
Reconstruction 관점에서 VQ-VAE의 결과를 보면 Figure 2에서 볼 수 있듯 기존 VAE보다 훨씬 개선된 성능을 보여준다. 기존 방법들이 continuous공간에서 학습하다보니 생성모델이 학습해야하는 분포가 매우 어려웠을 것이나 VQ-VAE의 경우 discrete한 형태로 유용한 code를 모아놓고 이를 조합하는 방식으로 바꾼 것인데 결과적으로 VQ-VAE의 접근이 유효했다고 보여진다.

자세히보면 디테일한 부분을 잃어버리긴 했으나 기존 VAE의 성능을 생각해볼때 분명 유의한 개선이다. 뿐만 아니라 audio나 video와 같은 sequence 모델에서도 유의한 생성을 보여줌으로써 VQ방식을 도입한 VAE의 가능성을 보여주었다.
Conclusion
이 논문에서는 VAE와 vector quantization을 결합해 효과적인 discrete latent representation을 학습하는 VQ-VAE를 제시하였다. VQ-VAE는 이후 생성모델들과 결합되어 엄청난 결과물들을 보여주게 된다.
Bibliography
Oord, Aaron van den, Oriol Vinyals, and Koray Kavukcuoglu. “Neural discrete representation learning.” arXiv preprint arXiv:1711.00937 (2017).