Don't Decay the Learning Rate, Increase the Batch Size

모델의 학습과정에서 learning rate을 줄이는 것은 실용적으로 자주 사용되는 테크닉이다. 직관적으로는 시간이 지나면서 optimal point에 가까워질 것이므로 학습 step을 줄이는 것으로 볼 수 있다. 이러한 상황에서 이 논문은 batch size를 키우는 것이 동일한 효과가 있음을 다양한 실험으로 보여준다.
Quoc V. Le그룹에서 2018년에 제출한 실용적인 논문이다. 딥러닝 모델을 훈련할 때 optimizer의 learning rate와 batch size를 정하는 것은 간단하지 않다. Learning rate을 키우면 학습은 빨라질 것이나 학습이 아예 무너져버릴 수도 있고 learning rate을 너무 작게 사용하면 학습이 오래 걸린다. Batch size의 경우도 큰 batch size를 사용하게 되면 parameter update의 빈도를 낮추어주어 학습속도를 빠르게 할 수 있지만 batch size를 크게 할 경우 generalization 성능이 떨어져 test set의 performance가 떨어진다는 것이 알려져 있다.
이 논문은 learning rate을 줄이는 것을 simulated annealing의 과정으로 본다. Simulated annealing은 optimization 방법의 하나로, 간단히 말하면 초반에 temperature가 높은 상태에서 random한 상태를 뽑으며 더 좋은 상태를 찾다가 시간이 지날 수록 temperature를 떨어뜨리면서 탐색부분을 서서히 줄여 최적점으로 수렴하게 만드는 기법이다. 이 논문에서는 simulated annealing의 방법인 learning rate decaying을 batch size를 키우는 것으로 치환해 동일한 효과를 얻을 수 있음을 주장한다.
A key contribution of our work is to demonstrate that decaying learning rate schedule can be directly converted into increasing batch size schedules, and vice versa; providing a straight forward pathway towards large batch training.
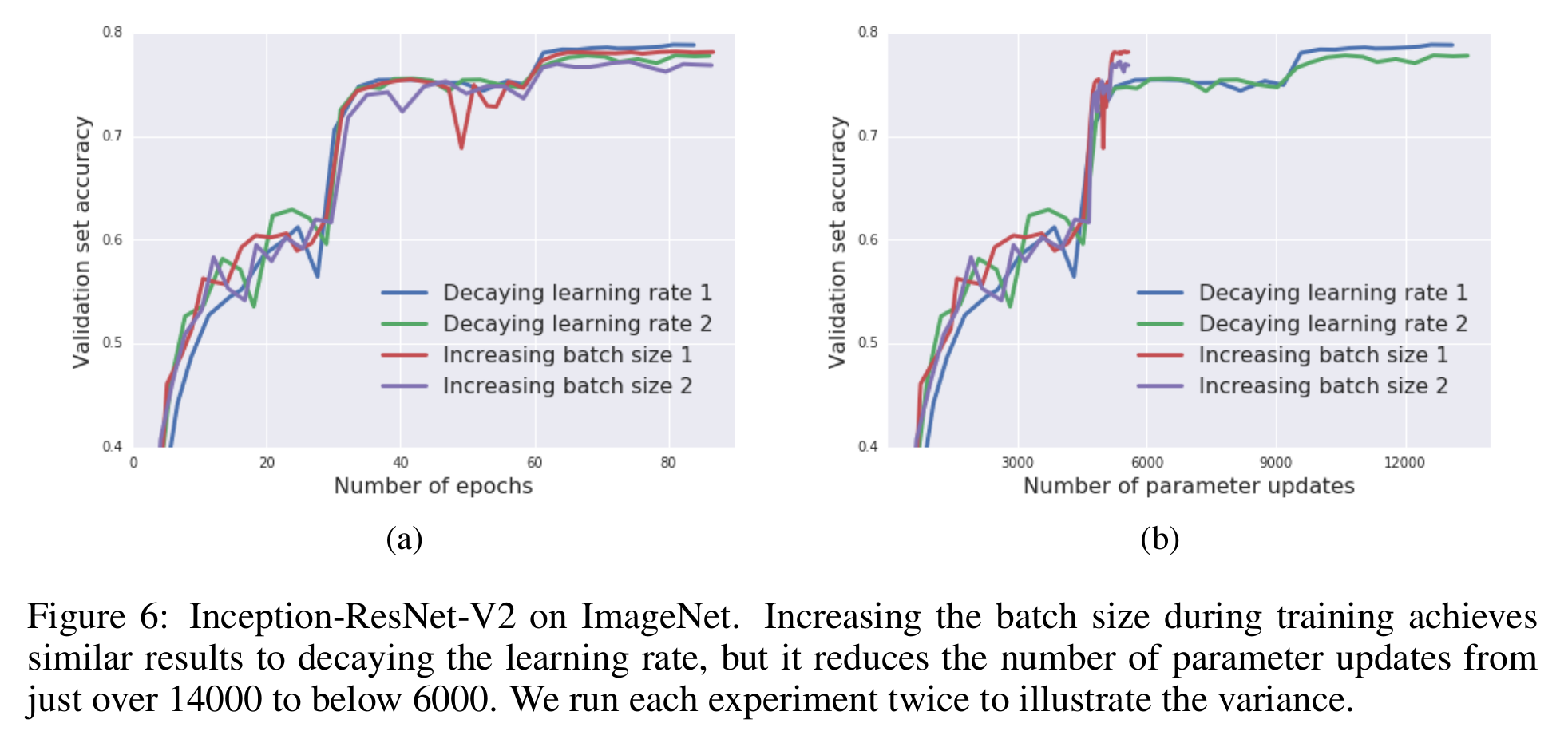
혼동하면 안되는 부분이 학습 중의 learning rate변화와 batch size변화에 관한 것이지 초기 값의 설정에 대한 것이 아니다. 이 논문은 학습하는 중에 learning rate decaying하는 대신, batch size를 키우는 방법으로 치환함으로써 학습 효율을 올릴 수 있다는 아주 실용적인 내용을 보인다. 그리고 이는 단순히 SGD optimizer뿐만이 아니라 momentum기반의 optimizer에도 적용되는 방법으로 자주 사용하는 Adam에도 동일하게 적용하면 된다.
실험에 따르면 이러한 방법으로 당시 ImageNet SOTA score를 TPU를 사용하는 환경에서 30분 안에 달성하는 것을 보여준다.
Bibliography
Smith, Samuel L., et al. “Don’t decay the learning rate, increase the batch size.” arXiv preprint arXiv:1711.00489 (2017).