Chapter 1: Introduction

강화학습을 다루기에 앞서 강화학습의 개괄적인 내용을 먼저 확인해보자.
Reinforcement Learning
교재에서는 강화학습을 다음과 같이 정의한다.
Reinforcement learning is learning what to do-how to map states to actions-so as to maximize a numerical reward signal.
즉, 보상신호(reward signal)가 최대가 되도록 상태(state)에서 행동(action)으로의 mapping을 학습하는 과정인 것이다.
Stanford의 CS234에서는 조금 더 추상적인 수준에서 다음과 같이 정의한다.
Intelligent agent which can learn to make good sequences of decisions.
강화학습은 주어진 일에 대해 좋은 순차적 의사결정을 하는 agent를 학습시키는 것으로, 순차적 의사결정을 푸는 접근방법의 하나로 볼 수 있다. 강화학습이 다루는 문제를 조금 더 세밀히 살펴보자.
Repeated Interactions with World
정의에서 하나의 의사결정이 아닌 순차적 의사 결정(sequences of decisions) 이라고 한 점을 유의해서 살펴보자. 강화학습은 단지 주어진 상황에서의 하나의 결정이 아닌 순서가 있는 결정을 내려야 한다. 이미지 분류문제를 예로 들면, 주어진 이미지에 대해 해당 이미지가 무엇에 대한 이미지인지만 구별하면 된다. 내부적으로 네트워크의 구성도 일련의 순서가 아니냐고 반문할 수 있지만 여기서의 순서란 결정(decisions)과정을 해당한다. Atari를 예로 들면, 게임의 한 장면을 보고 다음 결정을 내리게 되고, 그 결정에 대한 반응(장면)을 보고 또 다음의 결정을 내려야 한다. 다시말해, 한 장면이 아닌 한 게임(에피소드)에 대해서 결정을 내릴 수 있어야 한다.
Reward for Sequence of Decisions
그리고 이러한 일련의 결정은 당연하게도 좋아야한다. 마치 어떻게 해야 고수가 될 수 있냐는 질문에 대해 “잘"이라고 답하는 것 같지만 조금더 구체적인 의미에서 보면 위 정의에서의 good은 최적(optimal)의 결정 또는 보상을 높게 받는 결정임을 뜻한다.
Don’t know in Advance How World Works
마지막으로 학습할 수 있어야한다. 강화학습도 머신러닝의 갈래이다. 경험을 통해 스스로 “학습"할 수 있어야 한다. 그리고 머신러닝의 가장 근본적인 목표는 불확실성 속에서 좋은 결정을 내리는 방법을 학습하는 것이다.
Fundamental challenge in artificial intelligence and machine learning is learning to make good decisions under uncertainty.
2015년 Atari Game을 학습한 강화학습 알고리즘(DQN)은 기존 강화학습에 딥러닝을 결합하면서 패러다임의 전환을 만들어냈다. 사람과 동일한 시각정보(게임화면)만을 사용해 벽돌깨기게임에서 우수한 성능을 보여주었으며 심지어 터널을 뚫어 위로 올려버리는 전략을 학습하는 과정으로 크게 유명해졌다. 또한 로보틱스분야에서도 괄목할만한 성과를 냈다. UC Berkeley팀에서는 강화학습을 로봇팔에 적용해 물건을 집거나 옷을 개는작업까지도 학습을 시켰다. 만약 같은 문제를 일일이 규칙을 정의해 푼다고 했을 때, 가능성은 차치하고 수 많은 경우를 일일이 정의해야 하는 번거로움으로 사실상 구현이 어려울 것이다.
What Reinforcement Learning Involves
교재에서는 강화학습이 다른 학습방식과 차이를 보이는 특징으로 trial-and-error search와 지연보상으로 설명을 하고 있다. CS234는 이를 조금 더 세분화해서 네 가지 기준을 제시하므로 CS234에서 제시한 기준을 중심으로 살펴보자.
강화학습은 다음의 측면에서 다른 머신러닝방법과 구분된다.
-
최적화(Optimization)
강화학습의 목적은 결정을 내리는 최적의 방법/전략을 찾는 것이다.
-
Delayed consequences
결과가 즉각적으로 주어지지 않는다. 사람이 은퇴 이후를 위해 연금을 들고 장기적인 목적을 위해 단기적인 즐거움을 희생하는 것처럼 장기적인 보상을 위해 단기적인 보상을 희생하는 경우를 다룰 수 있어야 한다. 일례로, 정복이 어려웠던 Atari 게임 중 하나가 Montezuma’s revenge인데, 영상에서 볼 수 있듯 보상이 주어지기까지의 결정과정을 매우 많이 필요로한다. 즉, 단기보상뿐만이 아닌 장기보상을 극대화 하기 위한 planning과 특정 시점에서 추후의 보상을 향상시키는 학습에 있어 어려움이 따른다.
-
Exploration
Agent는 다양한 결정을 내리며 상호작용 속에서 학습하게 된다. 자전거를 탈 때 넘어지면서 속도가 있어야 균형을 유지한다는 사실을 익히듯, agent는 사전지식이 없거나 부족한 상태에서 목적을 달성하기 위한 전략을 학습해야한다. 즉 학습을 위해서는 새로운 시도를 해야한다.
You only get to learn about what you try to do.
-
Generalization
Generalization을 다루기에 앞서 정책(policy)에 대해 먼저 개략적으로 알면 유용하다. 정책은 과거 경험으로부터 현재의 행동으로의 함수이다. 그렇다면 모든 경우에 대해 정책을 구현해 놓는다면 최적의 결과를 얻을 수 있을 것이다. Atari의 벽돌깨기를 예로 들면, 공이 하강하는 모든 경우의 수에 대해 튕겨낼 수 있는 판을 움직이도록만해도 죽는 것을 방지할 수 있다. 즉 정책을 조건으로써 구현하고자 시도할 수 있다. 하지만 이렇게 간단했다면 알파고가 바둑에서 사람을 이겼다고 화제가 되지 않았을 것이다. 바둑의 어마어마한 경우의 수는 말할 것도 없고, Atari 벽돌깨기만 보아도 100 X 200 pixel의 게임에 RGB 색깔 3가지 채널을 가지므로 한 장면에서 가능한 상태는 다음과 같다. 각 pixel은 8bit로 $2^8=256$ 가지의 값을 갖도록 quantization한 것이다.
$$\left(256^{100 \times 200}\right)^3$$
심지어 이게 한 장면에서 나오는 경우의 수이다. 그러므로 우리는 모든 경우의 수에 대해 프로그램을 만드는 것이 아닌, 데이터를 그 자체로 받아들이고 사람이 말하는 전략 또는 high-level representation을 학습해 공략하는 것이 현실적이다.(참고로 2015년 Nature 논문에서 완전히 end-to-end로 한 것은 아니다. Resolution을 줄이고 채널도 흑백으로 바꾸어주는 등 상태공간을 줄이기 위한 수작업은 사용되었다.)
Comparison with Other Approaches
다양한 머신러닝의 학습방식과 강화학습의 학습방식 특징을 비교해보자.
Planning vs RL
Planning은 위의 성질 중 exploration이 제외된 최적화, generalization, delayed consequences 세 가지 성질을 갖는다. Good sequence of decisions를 찾는 목적도 동일하다. 하지만 중요한 차이점은 planning은 agent의 결정이 어떻게 환경에 작용하는지에 대한 모델이 주어진다는 점이 큰 차이점이고 그렇기에 exploration을 필요로 하지 않는다.
Supervised Learning vs RL
지도학습(Supervised Machine Learning)은 위의 성질 중 최적화, generalization의 두 가지 성질을 가지며 학습해야하는 target label이 있다는 점이 주된 차이점이다. 지도학습은 유용하게 사용되는 학습방식이나 상호작용하며 학습해야하는 상황에서는 적절하게 사용하기에는 부적절하다. 불가능하다고 단정적으로 말하기는 어려우나 “어떠한 상황에서 어떻게 해야 올바른 행동인지"를 학습용 sample로 모두 구성하는 것은 사실상 불가능하다고 볼 수 있다.
Unsupervised Learning vs RL
비지도학습(Unsupervised Machine Learning)은 위의 성질 중 지도학습과 동일하게 최적화와 generalization의 두 가지 성질을 가지나 지도학습과는 다르게 target label이 없다는 점에서 차이가 있다. 강화학습의 목적은 보상을 최대로 하는 것이고 비지도학습의 목적은 label이 없는 데이터의 구조/특징/패턴을 찾아내는 것이라는 점에서 강화학습과 비지도학습은 다른 목적을 갖는다.
Imitation Learning vs RL
Imitation learning은 planning처럼 최적화, generalization, delayed consequences 세 가지 성질을 가지나 앞의 학습방식들과는 다르게 agent 자체의 경험뿐만이 아니라 다른 intelligent agent의 결정과 결과를 관찰하면서 학습할 수 있다. 따라서 직접적으로 exploration을 하지 않을 수 있다. Imitation learning은 강화학습을 지도학습의 도메인으로 가지고 올 수 있다는 점에서 문제에 접근할 수 있는 도구를 확대해주고, exploration에서 생길 수 있는 문제를 해소한다는 장점이 있다.
Sequential Decision Making Under Uncertainty
강화학습은 상호작용하는 닫힌 시스템으로 생각할 수 있다. Agent가 있으며 이 agent의 행동은 환경(environment)에 영향을 주고 환경은 다시 agent에게 새로운 상태와 보상을 제공한다.
이를 도식화 한 것이 바로 다음의 그림이다.

Wikipedia: Reinforcement Learning
Agent의 목표는 총 보상의 기대값을 최대로 하는 방법을 찾는 것이다.
Goal: Select actions to maximize total expected future reward
Time step별로 정리하면 각 time step $t$마다 다음의 순서대로 진행된다.
- Agent가 행동 $a_t$를 실행한다.
- 환경은 입력으로 행동 $a_t$를 받고 변화된 환경 $o_t$와 보상 $r_t$를 출력으로 내보낸다.
- Agent는 $o_t$와 $r_t$를 입력으로 받는다.
이러한 절차를 반복적으로 거치게 되면 history는 행동과 관찰한 상태, 보상에 대한 기록으로써 다음처럼 저장된다.
$$h_t = (a_1, o_1, r_1, \ldots, a_t, o_t, r_t)$$
다음 상태는 그 동안의 history에 의해 결정된다는 점에서 history의 함수라고 말할 수도 있다.
Markov Assumption
강화학습은 learning agent와 환경의 상태, 행동, 보상간 상호작용을 정의하기위해 Markov Decision Process(MDP) framework을 사용한다. 따라서 강화학습을 이해하기 위해서는 MDP에 대한 이해가 바탕이 되어야 한다.
강화학습문제들은 Dynamical systems theory에서 다루는 incompletely-known Markov decision processes에 대한 optimal control문제로 구성해 볼 수 있다. 이에 대한 세부적인 내용은 교재 Chapter 3의 주된 주제이므로 여기서는 Markov Decision Process(MDP)와 이를 구성하는 기본 가정에 대해 가볍게 살펴보자.
Markov assumption은 각 상태에서 다음 상태가 오직 현재상태로부터만 영향을 받고 과거의 상태로부터는 독립적인 성질을 말한다. 다시 말해, $S_{t+1}$은 $S_{t-1}$과는 독립적이고 $S_t$로부터만 영향을 받는다. 이러한 성질을 만족하는 process를 Markov Process라고 한다.
$$p(s_{t+1} \vert s_t, a_t) = p(s_{t+1} \vert h_t, a_t)$$
이렇게만 생각해보면 세상에 Markov Property를 만족하는 것은 별로 없어보인다. 내일의 결과는 오늘뿐만이 아니라 어제의 영향도 받을 것이고, 음악추천서비스가 내게 추천해주는 다음곡은 현재 듣고있는 곡뿐만이 아닌 과거에 들은 곡들도 감안할 것이다. 매우 제한적이다. 하지만, history를 상태로 생각하면($s_t = h_t$) Markov assumption을 항상 만족하게 할 수 있다. 실제 문제에서는 흔히 가장 최근의 관측을 sufficient statistic of history로 설정하기도 한다. 위에 언급된 Atari를 예로 들면, DQN 알고리즘은 최근 4개의 관측결과를 상태로 사용하였다. 즉, 최근 4개의 history를 하나의 상태로 취급하여 Markov assumption을 만족시킨 것으로 이해할 수 있다.
Markov Models
Markov Model은 크게 다음 질문들에 대한 Yes/No 여부에 따라 네가지 종류로 나눌 수 있다.
- States are completely observable?
- Do we have control over the state transitions?
각각의 기준을 먼저 살펴보자. 상태가 completely observable하다는 것은 무엇일까? 현재, 환경에서 상태를 내가 인지할 수 있는 예는 보드게임들이 있을 것이다. 체스나 바둑을 생각해보면 나의 상태를 상태공간에서 정확하게 특정할 수 있다. 하지만 스타크래프트와 같은 게임을 생각해보자. 플레이어가 알 수 있는 곳은 시야가 확보된 지역에 한정된다. 시야가 없거나, 정찰을 했더라도 현재 시야가 없으면 그 곳에서 어떤 일이 일어나는지를 모른다. 이런 상태를 partially observable하다고 한다.
그 다음 기준인 Do we have control over the state transitions?에 대해 생각해보자. 문자 그대로 state transition에 개입을 할 수 있는지 여부이다. 슬롯머신 앞에 앉아있다고 생각해보자. 레버가 없는 슬롯머신이며 결과가 나오면 자동으로 다음 게임이 진행된다고 가정하면, 플레이어는 현재 상태에서 다음 상태로 선택의 여지 없이 넘어가게 된다. 즉, control할 수 없는 상태인 것이다. 다른 슬롯머신은 레버가 세 개가 있고 각 레버는 다음 상태에 영향을 준다고 해보자. 이 때 플레이어가 어떤 레버를 당길지 고를 수 있다면 이는 state transition에 대해 control을 할 수 있는 상태이다.
이를 염두에 두고 다음 네가지 Markov model을 알아보자.
Markov Chain

- 유한한 discrete 상태를 갖는다.
- 상태간 transition이 확률적으로 정의된다.
- 다음 상태는 현재 상태에 의해서만 결정된다. (과거 상태에 대해 확률적으로 독립이다)
Hidden Markov Model (HMM)
- 유한한 discrete 상태를 갖는다.
- 상태간 transition이 확률적으로 정의된다.
- 다음 상태는 현재 상태에 의해서만 결정된다. (과거 상태에 대해 확률적으로 독립이다)
- 현재의 상태를 모른다.
Markov Decision Process (MDP)

- 유한한 discrete 상태를 갖는다.
- 상태간 transition이 상태와 행동에 대해 확률적으로 정의된다.
- 다음 상태는 현재 상태와 현재 행동에 의해서만 결정된다. (과거 상태와 행동에 대해 확률적으로 독립이다)
Partially Observable Markov Decision Process (POMDP)
- 유한한 discrete 상태를 갖는다.
- 상태간 transition이 상태와 행동에 대해 확률적으로 정의된다.
- 다음 상태는 현재 상태와 현재 행동에 의해서만 결정된다. (과거 상태와 행동에 대해 확률적으로 독립이다)
- 현재의 상태를 모른다.
Markov Model Summary
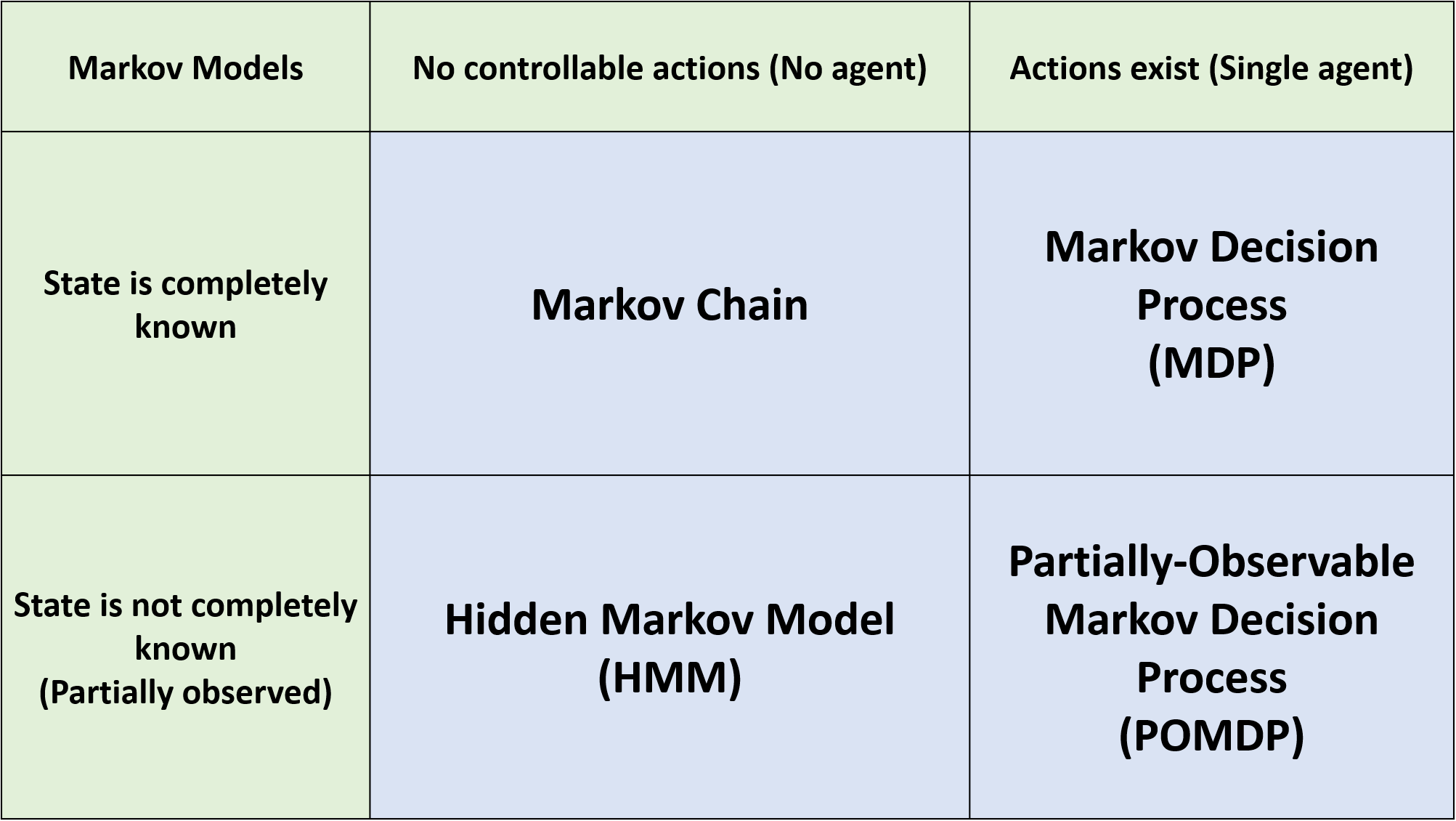
Types of Sequential Decision Processes
Bandits
- 행동이 다음 관측에 영향을 주지 않는다.
- 보상이 즉각적으로 주어진다.
MDP and POMDP
- 행동이 다음 관측에 영향을 준다.
- 지연보상이 있으므로 credit assignment(특정 결과를 얻기 위한 행동을 푸는 문제)나 전략적인 행동(strategic action)을 사용한다.
How the World Changes
환경의 특성에 따라 deterministic한 환경 혹은 stochastic한 환경으로 나누어진다.
- Deterministic 주어진 history와 행동에 대해서 하나의 관측과 보상이 주어진다. 주로 robotics나 control쪽에서 이와 같은 가정을 한다.
- Stochastic 주어진 history와 행동에 대해 다수의 가능한 관측과 보상이 존재한다. 주로 환경에 대한 model을 구성하기 어려운 문제들이 이에 해당한다.
RL Algorithm Components
강화학습을 구성하는 요소들에 대해서 살펴보자. 강화학습을 구성하고 있는 요소는 정책(policy), 보상신호(reward signal), 가치함수(value function) 가 있으며 환경에 대한 모델(model) 은 포함될 수도, 포함되지 않을 수도 있다. Model을 갖는 경우를 model-based라고하며 model이 없는 경우를 model-free라고 한다.
Policy
정책(policy)는 agent의 상태에서 행동으로의 mapping이다. 정책 $\pi$에 의해 agent가 어떤 행동을 고를지가 결정된다.
$$\pi: S \rightarrow A$$
Deterministic policy
상태에서 하나의 행동으로 mapping된다. $$\pi(s) = a$$
Stochastic policy:
상태에 대해서 행동의 확률분포로 mapping된다. $$\pi(a \vert s ) = Pr(a_t = a \vert s_t = s)$$
Reward Signal
보상신호(reward signal)는 강화학습문제의 목표를 정의한다. 매 시점마다 환경은 강화학습 agent에게 보상이라고 불리는 신호를 보낸다. 그리고 이 신호는 스칼라 값이다. 총 보상의 합(return)을 가장 크게 만드는 것이 강화학습 agent의 궁극적인 목표이다.
Value Function
보상신호가 행동에 대한 환경의 즉각적인 반응(immediate response)으로서 좋고 나쁨을 알려준다면 가치함수는 장기적인 관점에서 좋고 나쁨을 정의한다. 가치함수 $V^{\pi}$는 정책 $\pi$를 따를 때 해당 상태/행동을 통해 얻을 수 있는 미래 보상에 대한 기댓값이다.
$$V^{\pi}(s_t = s) = \mathbb{E}_{\pi}[r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots \vert s_t = s]$$
위에서 확인할 수 있듯, 가치함수는 하나의 보상이 아닌 보상의 총합에 대한 기댓값으로써 정의된다. 따라서 가치함수를 통해 상태와 행동에 대한 좋음과 나쁨의 정도를 정량화 할 수 있다. 또한, discount factor $\gamma$에 의해 현재 보상과 미래 보상의 균형을 조절할 수 있다. 극단적으로 $\gamma=0$이면 현재 보상만 고려하는 근시안적 접근이 될 것이고 $\gamma=1$이면 미래보상과 현재보상을 동등하게 반영한다.
Model
강화학습을 구성하는 마지막 요소는 모델(model)이다. Model은 환경이 agent의 행동에 대해 어떻게 반응하는지를 표현한다.
- 다음 상태를 예측하는 transition/dynamics 모델은 다음과 같이 표현할 수 있다. $$p(s_{t+1} = s^\prime \vert s_t = s, a_t = a)$$
- 현재 보상을 예측하는 reward model은 다음과 같이 표현할 수 있다. $$r(s_t = s, a_t = a) = \mathbb{E}[r_t \vert s_t = s, a_t = a]$$
Model이 있는 경우, 다음 상태와 보상을 직접 경험하지 않고도 예측해 볼 수 있으므로 planning분야에서는 model을 활용하여 가능한 미래 상황을 고려해 행동을 결정할 수 있다.
Types of RL Agents
강화학습 agent의 종류는 model의 사용여부에 따라 model-based와 model-free 두 가지로 나눌 수 있다. Model-based는 이름에서 의미하듯 모델을 통해 정책과 가치함수를 가질 수 있다. Openai의 강화학습 튜토리얼인 Spinning up에서도 model 유무에 따라 구분하고 있다.

Evolutionary Methods vs RL (Value Function Estimation)
대부분의 강화학습문제는 가치함수를 잘 추정(estimate)하는 문제로 귀결된다. 하지만 반드시 문제의 해결을 위해서 가치함수를 사용해야 하는 것은 아니다. Evolutionary methods 중 Genetic algorithms, Genetic programming, Simulated annealing 등은 가치함수를 추정하지 않고 문제를 해결한다.
가치함수를 사용하는 강화학습과 evolutionary methods의 가장 큰 차이점은 중간과정의 반영여부이다. 예를 들어, 체스, 바둑과 같은 게임은 승, 패가 결정되기까지 말의 이동이 여러단계에 걸쳐서 일어난다. 학습과정에서 evolutionary methods는 다양한 정책을 고정한 채로 게임을 진행해 승률에 따라 다음 정책 선택을 결정한다. 하지만 승률을 적절하게 추정하기위해서는 한 정책으로도 많은 게임을 해보아야 한다. (같은 전략이 계속 먹히는지 한 두판만 해서 결정할 수 는 없다) 그리고 evolutionary methods에서는 최종결과인 게임의 승패만이 해당 정책의 승률로서 저장된다. 여기서 중요한 점은 게임 중에 일어난 과정들은 무시된다는 것이다. 다시 말해, 게임을 승리로 이끈 결정적인 수가 어떤 것이었는지는 고려되지 않고 단지 승리하게 된 게임의 모든 행동들이 높은 점수를 받게 되는 것이다. 이는 가치함수기반의 접근에서 한 게임 내에서 각각의 상태를 평가하는 것과는 대조적이다.
결국 evolutionary methods와 가치함수기반 방법 모두 정책공간을 탐색한다는 점에서는 같지만 가치함수는 한 게임 내에서 일어났던 정보들을 이용할 수 있다는 점에서 차이가 있다. 또한 이러한 차이는 강화학습이 환경과 상호작용한다는 점과 지연된 보상을 감안한 목표달성을 반영한다는점을 분명히 보여준다.
Key Challenges in Learning to Make Sequences of Good Decisions
그렇다면 순착적 의사결정문제를 푸는 학습과정에서의 어려운 점은 어떤 것이 있을까? Planning과 강화학습으로 구분해서 확인해보자.
Planning
Planning은 환경이 어떻게 작동하는지에 대한 Model이 있다는 점에서 그렇지 않은 경우보다 수월한 부분이 있다. 하지만 Model은 model일 뿐이며 실제 환경은 아니다. 실제 환경과 model이 괴리가 있다면 학습과정에서의 어려움을 차치하더라도 model의 오차로 인해 학습이 어려워질 수 있다.
Planning의 예로 예전 Windows에 기본으로 깔려있던 Solitaire 카드놀이를 들 수 있다. Solitaire는 Clova/Heart/Spade/Diamond별로 정렬시키면 되는 게임이다. 사용자의 행동에 대한 환경의 반응, 즉 model도 명확하다. 최적의 행동을 구하기 위해 model이 있다는 점을 이용해 이후 다루게 될 dynamic programming이나 tree search등의 방법을 사용할 수 있다.
Reinforcement Learning
Planning과는 다르게 강화학습에서 어려운 점은 실제 세계가 어떻게 작동하는지 모른다는 것이다. 오목이라는 게임의 규칙을 알고 학습하는 것이 Planning이라면 강화학습에서는 오목에 대한 룰도 없이 그저 수많은 시도를 통해 오목이란 어떤 게임인가에 대해 알아내야 한다. 따라서 직/간접적으로 실제 세계(예시에서는 오목의 규칙)의 작동원리를 알아내야 한다. 이렇게 작동원리를 알아냈다면 이를 기반으로 정책을 향상시켜 나아갈 수 있다.
Solitaire 예시를 이어가면 강화학습에서는 Solitaire가 어떤 게임인지 모르는 상태에서 학습한다고 보면된다. 카드를 올바른 순서가 되도록 놓아야 보상이 발생할 것이고 이러한 보상을 통해 Solitaire가 어떤 게임인지를 알아내는 것 또한 강화학습에서는 학습과정에 포함된다.
Exploration and Exploitation
강화학습의 주요한 특징 중 하나는 Exploration-exploitation trade-off이다. 강화학습 agent는 상호작용을 통해 학습하므로 행동을 취하는 전략은 중요한 문제이다. 이때 행동을 취하는 방식은 두 가지로 나누어 볼 수 있다.
첫번째는 exploration이다. 새로운 행동을 취함으로써 미래에 보상을 크게 할 수 있는 더 좋은 방법을 찾아낼 수 있다. 특히 문제에 대해 사전지식이 없다면 exploration을 통해 정책을 향상시켜야 한다. 하지만 극단적으로 exploration을 하면 매번 새로운 행동만 취하고 정작 학습한 내용은 잘 활용하지 못하게 될 것이다.
두번째는 exploitation이다. 과거 경험을 통해 가장 좋은 보상을 받을 수 있는 방법을 선택하는 행동을 exploitation이라고 한다. 다양한 점심메뉴를 시도(exploration)했으면 이후에는 가장 만족도가 높은 메뉴를 자주 먹게(exploitation) 될 것이다.
Policy Evaluation and Control
Policy evaluation은 특정 정책에 대한 가치함수를 결정하는 과정이다.
$$ \pi \rightarrow v_{\pi} $$
Control은 가능한한 큰 보상을 받을 수 있는 정책을 찾는 작업으로 정책을 향상시키는 작업을 포함한다. 따라서 Control은 강화학습에서의 궁극적인 목표이기도 하다. 자세한 내용은 Dynamic programming에서 다루도록 한다.
Conclusion
이번 포스팅에서는 강화학습의 기본적인 내용들을 알아보았다. 한꺼번에 많은 개념이 등장하였지만 이후 단원들에서 순차적으로 다룰 내용이므로 부담없이 읽는 정도로 충분하다고 생각한다.